Weights & Biases¶
We show how LaminDB can be integrated with W&B to track the training process and associate datasets & parameters with models.
# !pip install 'lamindb[jupyter]' torchvision lightning wandb
!lamin init --storage ./lamin-mlops
!wandb login
import lamindb as ln
import wandb
import lightning
from torch import utils
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from autoencoder import LitAutoEncoder
ln.track()
Define a model¶
We use a basic PyTorch Lightning autoencoder as an example model.
Code of LitAutoEncoder
Simple autoencoder model¶
import torch
import lightning
from torch import optim, nn
class LitAutoEncoder(lightning.LightningModule):
def __init__(self, hidden_size: int, bottleneck_size: int) -> None:
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, bottleneck_size),
)
self.decoder = nn.Sequential(
nn.Linear(bottleneck_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 28 * 28),
)
self.save_hyperparameters()
def training_step(
self, batch: tuple[torch.Tensor, torch.Tensor], batch_idx: int
) -> torch.Tensor:
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
self.log("train_loss", loss)
return loss
def configure_optimizers(self) -> optim.Optimizer:
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
Query & download the MNIST dataset¶
We saved the MNIST dataset in curation notebook which now shows up in the Artifact registry:
ln.Artifact.filter(kind="dataset").df()
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 1 | 9YvhPw3lKenhXIk20000 | testdata/mnist | None | dataset | None | 54950048 | amFx_vXqnUtJr0kmxxWK2Q | 4 | None | md5-d | True | True | 1 | 1 | None | None | True | 1 | 2025-07-14 06:39:56.727000+00:00 | 1 | {'af': {'0': True}} | 1 |
You can also find it on lamin.ai if you were connected your instance.
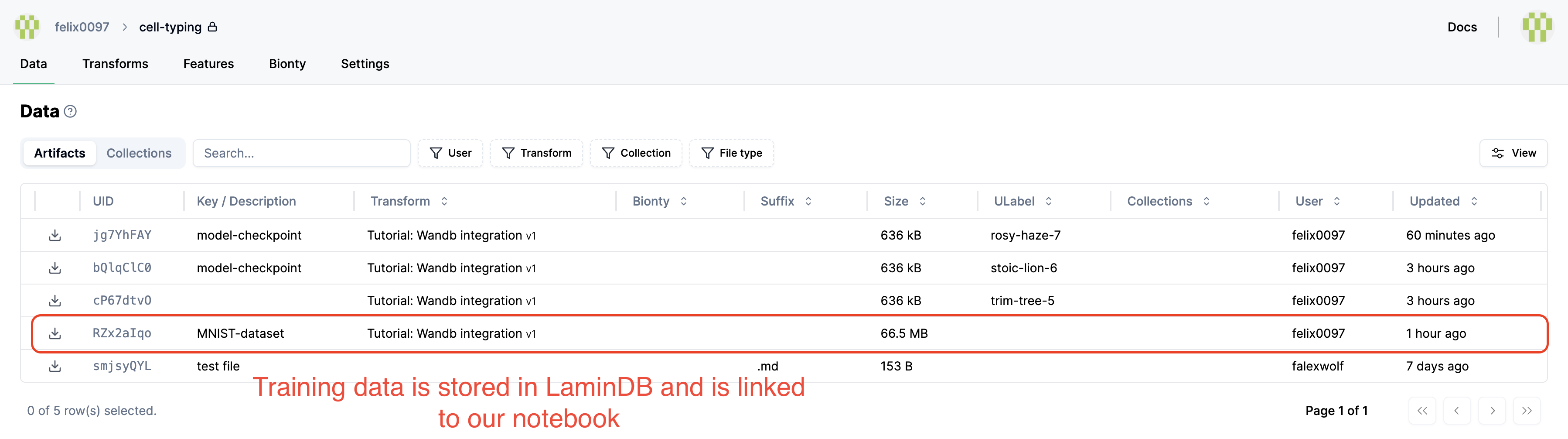
Let’s get the dataset:
artifact = ln.Artifact.get(key="testdata/mnist")
artifact
And download it to a local cache:
path = artifact.cache()
path
Create a PyTorch-compatible dataset:
dataset = MNIST(path.as_posix(), transform=ToTensor())
dataset
Monitor training with wandb¶
Train our example model and track the training progress with wandb.
from lightning.pytorch.loggers import WandbLogger
MODEL_CONFIG = {"hidden_size": 32, "bottleneck_size": 16, "batch_size": 32}
# create the data loader
train_loader = utils.data.DataLoader(
dataset, batch_size=MODEL_CONFIG["batch_size"], shuffle=True
)
# init model
autoencoder = LitAutoEncoder(
MODEL_CONFIG["hidden_size"], MODEL_CONFIG["bottleneck_size"]
)
# initialize the logger
wandb_logger = WandbLogger(project="lamin")
# add batch size to the wandb config
wandb_logger.experiment.config["batch_size"] = MODEL_CONFIG["batch_size"]
from lightning.pytorch.callbacks import ModelCheckpoint
# store checkpoints to disk and upload to LaminDB after training
checkpoint_callback = ModelCheckpoint(
dirpath=f"model_checkpoints/{wandb_logger.version}",
filename="last_epoch",
save_top_k=1,
monitor="train_loss",
)
# train model
trainer = lightning.Trainer(
accelerator="cpu",
limit_train_batches=3,
max_epochs=2,
logger=wandb_logger,
callbacks=[checkpoint_callback],
)
trainer.fit(model=autoencoder, train_dataloaders=train_loader)
wandb_logger.experiment.name
wandb_logger.version
wandb.finish()
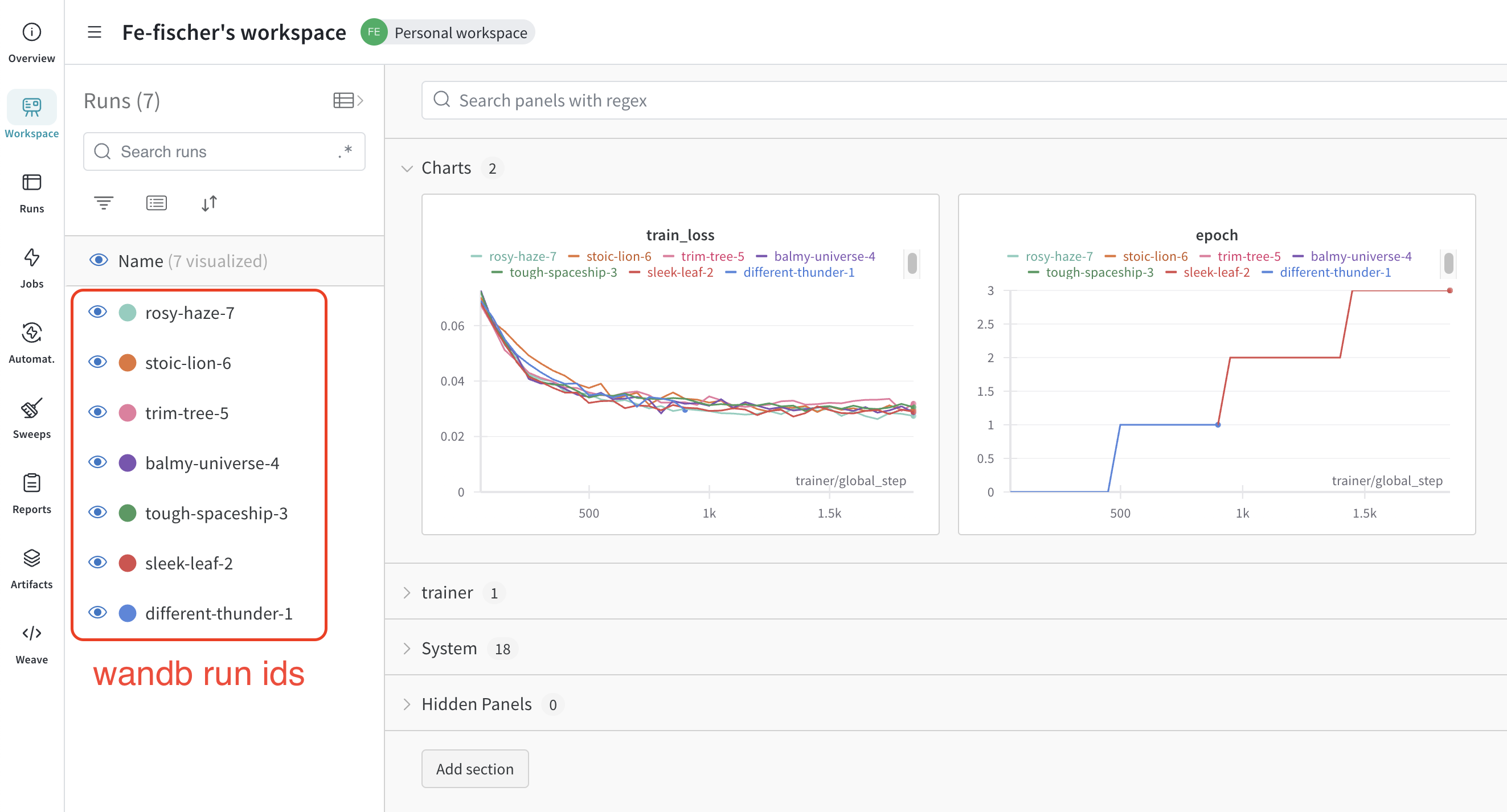
See the training progress in the wandb UI:
Save model in LaminDB¶
# save checkpoint as a model in LaminDB
artifact = ln.Artifact(
f"model_checkpoints/{wandb_logger.version}",
key="testmodels/wandb/litautoencoder", # is automatically versioned
type="model",
).save()
# create a label with the wandb experiment name
experiment_label = ln.ULabel(
name=wandb_logger.experiment.name, description="wandb experiment name"
).save()
# annotate the model artifact
artifact.ulabels.add(experiment_label)
# define the associated model hyperparameters in ln.Param
for k, v in MODEL_CONFIG.items():
ln.Param(name=k, dtype=type(v).__name__).save()
artifact.params.add_values(MODEL_CONFIG)
# look at Artifact annotations
artifact.describe()
artifact.params
See the checkpoints:
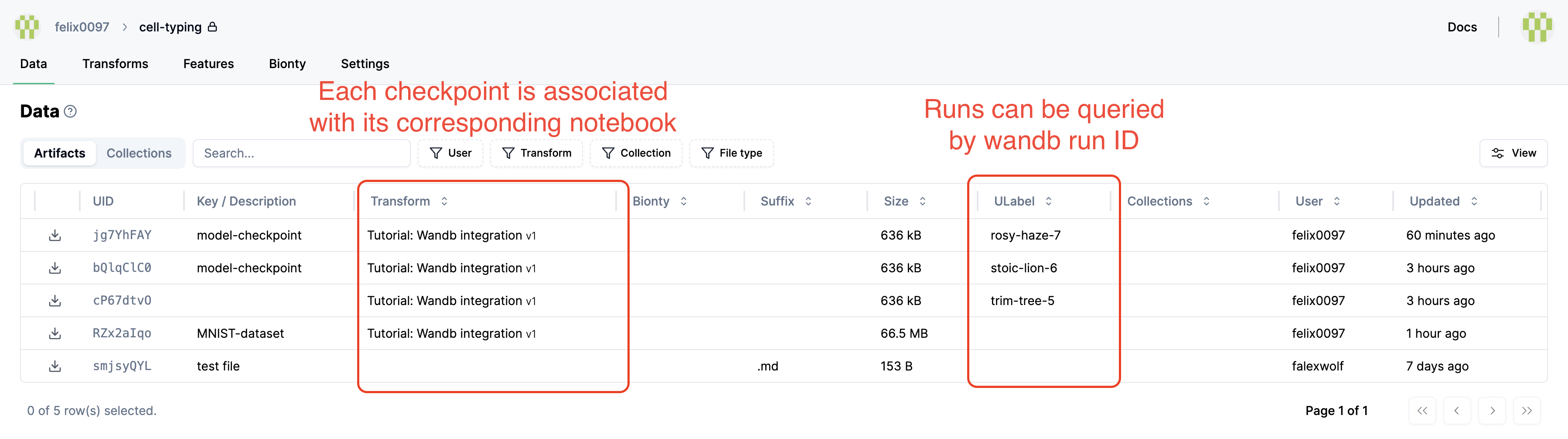
If later on, you want to re-use the checkpoint, you can download it like so:
ln.Artifact.get(key="testmodels/wandb/litautoencoder").cache()
Or on the CLI:
lamin get artifact --key 'testmodels/litautoencoder'
ln.finish()